Running Program in Series Vs Parallel
Running your jobs in series means that every task will be executed one after the other (serially). You can take advantage of the cluster even better when running your jobs in parallel than in series. This way, you could execute much more tasks at once (simultaneously) and achieve a faster result.
Serial programs
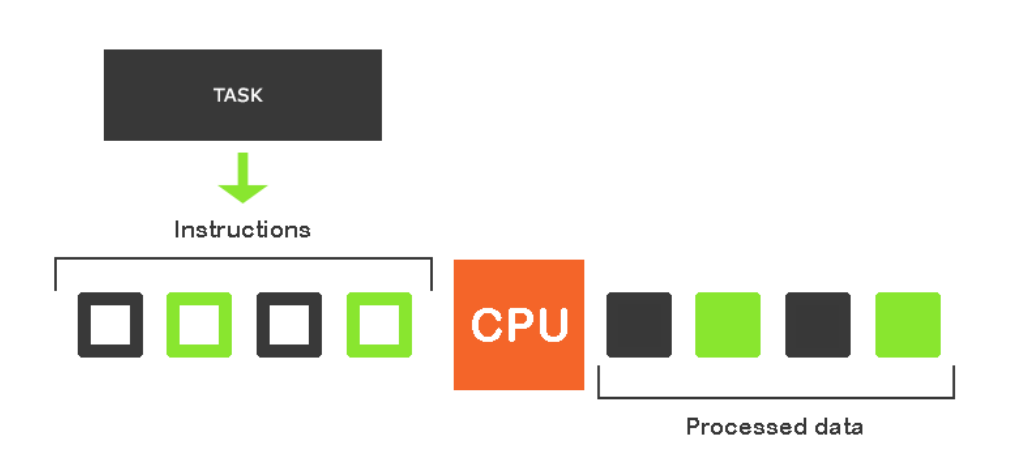
The image above depicts how a task is serially executed by a single processor. This is okay for trivial applications with a simple calculation that doesn’t require much processing power or speed. But, imagine that you want to run high computational programs that are time demanding and require much more processing speed and power. In such cases, you may have to consider going parallel to achieve results faster.
Parallel Programs
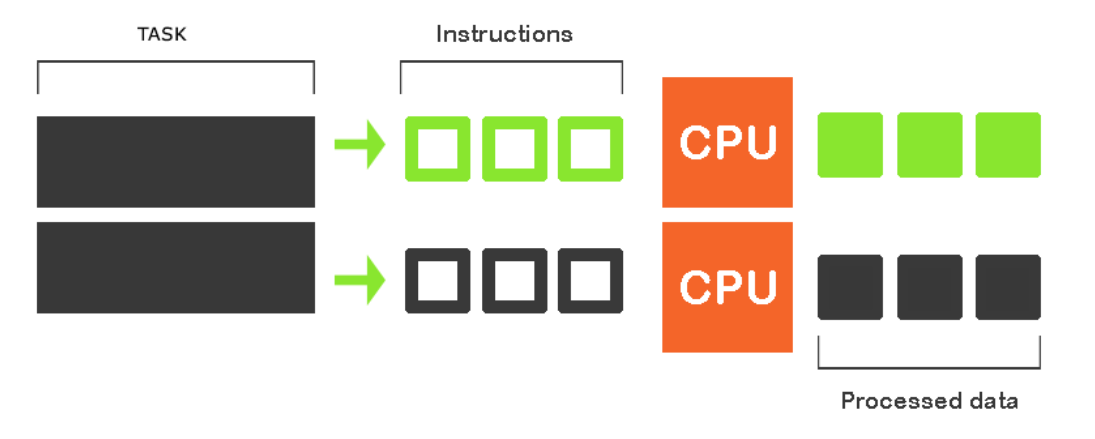
Parallel computing involves having two or more processors solving a single problem. The image above depicts how multiple tasks are being executed by multiple CPUs. The more CPUs you add, the faster the tasks get done.
Note that a program that doesn’t have any form of Parallelization or Parallel API Implementation won’t take advantage of utilizing multiple CPUs.
Sequential Execution
Running program in series means that one job needs to be finished until the next starts. These two jobs would be dependent. Below is a sample script of running jobs sequentially. Please note that the lines prefixed with the double pound signs are comments.
#!/bin/bash
#SBATCH --job-name testJob ## Name of your job
#SBATCH --output testJob.out ## The output file of your job
#SBATCH --ntasks 1 ## Number of tasks to run
#SBATCH --cpus-per-task 1 ## Number of CPUS to use per a task
#SBATCH --mem-per-cpu 1024M ## Amount of memory allocated per CPU
#SBATCH --time 00:10:00 ## The wall time for your job
## Your program's dependency
module load matlab/r2017a
## Change directories
cd somePath/subPath
## This executes first
srun matlab matlabProgram.m
## This executes next
srun /pathToMyProgram/myFavProgram myFavProgram.shParallel Execution
If you want to run several independent jobs, you can make them parallel. One method is to create a file with instructions on what has to be done simultaneously and independently. For example, the file with instructions will be named myfile.conf.
Method 1
|
Make sure the number of tasks matches the number of tasks in your SBATCH script. |
#!/bin/bash
#SBATCH --job-name maxFib
#SBATCH --output maxFib.out
#SBATCH --ntasks 2
#SBATCH --cpus-per-task 2
#SBATCH --mem-per-cpu 500M
#SBATCH --time 10:00
## Load the python module
module load python/3.7.0-gcc-8.2.0
## Initiate the multiple program parameter and load the instructions in the myfile.conf file
srun --preserve-env --multi-prog ./myfile.conf0 python script.py 90
1 python script.py 70The example above has the format:
#taskId <program> <script> <input>Method 2
This method doesn’t require you to have an external file that contains instructions to be executed. You can specify your instructions as shown below.
#!/bin/bash
#SBATCH --job-name maxFib
#SBATCH --output maxFib.out
#SBATCH --ntasks 4
#SBATCH --cpus-per-task 1
#SBATCH --mem-per-cpu 100M
#SBATCH --time 10:00
## Load the python interpreter
module load python/3.7.0-gcc-8.2.0
## Execute the python script
srun -n 1 python script.py 90 &
srun -n 1 python script.py 20 &
srun -n 1 python script.py 30 &
srun -n 1 python script.py 10 &
waitIn the above script, 4 tasks are specified and allocated 1 CPU per task which makes it a total of 4 CPUs for the entire job. Notice that the same script (script.py) is executed each time but passing different arguments per every job step.