Slurm Commands
Commands List
Slurm offers many commands you can use to interact with the system and retrieve helpful information about your job. Below is the list of the common Slurm commands:
| Commands | Syntax | Description |
|---|---|---|
|
|
Submit a batch script to Slurm for processing. |
|
|
Show information about your job(s) in the queue. The command when run without the |
|
|
Run jobs interactively on the cluster. |
|
|
End or cancel a queued job. |
|
|
Show information about current and previous jobs. |
|
|
Get information about the resources on available nodes that make up the HPC cluster. |
The screenshot below depicts an example use of all the commands
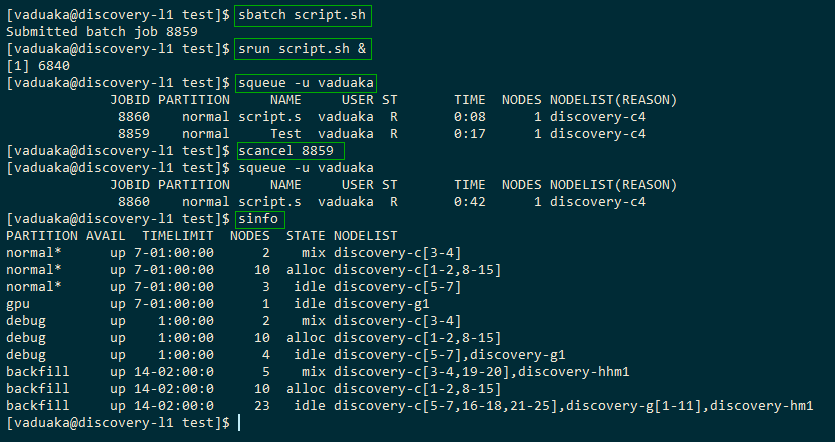
The sinfo Command
The sinfo command gives an overview of the resources offered by the cluster. It lists the partitions that are available. A partition is a set of compute nodes grouped logically. This command can answer questions: How many nodes are at maximum? What are my chances of getting on soon?
Syntax: sinfo or sinfo --[optional flags]
sinfoOutput
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
normal* up 7-01:00:00 8 mix discovery-c[1-2,8-13]
normal* up 7-01:00:00 7 idle discovery-c[3-7,14-15]
gpu up 7-01:00:00 1 mix discovery-g[1,16]
interactive up 1-01:00:00 4 idle discovery-c[34-35],discovery-g[14-15]
backfill up 14-02:00:0 10 mix discovery-c[1-2,8-13,16],discovery-g[1,16]
backfill up 14-02:00:0 42 idle discovery-c[3-7,14-15,17-35],discovery-g[2-15],discovery-c[37-38]The output above shows a list of the partitions on the Discovery cluster that you are only authorized to use.
Example with --all flag
sinfo --allOutput
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
normal* up 7-01:00:00 11 mix discovery-c[1-5,8-13]
normal* up 7-01:00:00 4 idle discovery-c[6-7,14-15]
gpu up 7-01:00:00 1 mix discovery-g[1,16]
interactive up 1-01:00:00 4 idle discovery-c[34-35],discovery-g[14-15]
backfill up 14-02:00:0 13 mix discovery-c[1-5,8-13,16],discovery-g1
backfill up 14-02:00:0 39 idle discovery-c[6-7,14-15,17-35],discovery-g[2-15],discovery-c[37-38]
iiplab up 7-01:00:00 1 idle discovery-g7
cfdlab up 7-01:00:00 1 mix discovery-c16
cfdlab up 7-01:00:00 14 idle discovery-c[17-25],discovery-g[2-6]
cfdlab-debug up 1:00:00 1 mix discovery-c16
cfdlab-debug up 1:00:00 14 idle discovery-c[17-25],discovery-g[2-6]
osg up 1-01:00:00 13 mix discovery-c[1-5,8-13,16],discovery-g[1,16]
osg up 1-01:00:00 35 idle discovery-c[6-7,14-15,17-33],discovery-g[2-13],discovery-c[37-38]
covid19 up 1-01:00:00 13 mix discovery-c[1-5,8-13,16],discovery-g[1,16]
covid19 up 1-01:00:00 35 idle discovery-c[6-7,14-15,17-33],discovery-g[2-13],discovery-c[37-38]The output above shows a list of the entire partition on the Discovery cluster.
Header Explained
| Header | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
|
The list of the cluster’s partitions. It’s a set of compute nodes grouped logically |
||||||||
|
The active state of the partition. (up, down, idle) |
||||||||
|
The maximum job execution |
||||||||
|
The total number of nodes per partition. |
||||||||
|
|
||||||||
|
The list of nodes per partition. |
The squeue Command
The squeue command is used to show how resources are currently allocated (For example, which node is used by which job). It shows the list of jobs which are currently running ® or waiting for resources (pending- PD). It answers questions like: Where are you in the queue? How long has my job been running?
squeueSyntax: squeue -u <username>
$ squeue -u vaduakaOutput
~JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
219373 normal camelCas vaduaka PD 0:00 1 (Resources)
219370 normal maxFib vaduaka R 0:01 1 discovery-c14
219371 normal camelCas vaduaka R 0:01 1 discovery-c14
219372 normal maxFib vaduaka R 0:01 1 discovery-c14The information shown from running the squeue command shows only your own jobs in the queue because the -u flag and username was passed as an argument.
If you want to see a list of all jobs in the queue, you can use only the squeue command. This will reveal a list of all the jobs running on the partition you are authorized to access. You wouldn’t be able to see all other jobs running on other partitions except you use the --all flag.
-
Example with squeue
$ squeueOutput summary
~JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 218983 normal run.sh viviliu PD 0:00 1 (Resources) 219407 normal run.sh viviliu PD 0:00 1 (Priority) 217794 normal JackNema cvelasco R 1-05:28:58 1 discovery-c14 218985 normal HWE gsmithvi R 1:03:57 1 discovery-c12 215745 normal S809f bryanbar R 5-03:25:57 3 discovery-c[9,11,13] 217799 normal LPT pcg1996 R 1-05:15:04 6 discovery-c[2-4,6-8] 214915 normal run.sh viviliu R 4-19:25:13 2 discovery-c[1,6] 216157 backfill BatComp jmwils R 2-05:48:53 1 discovery-g10 218982 normal run.sh viviliu R 4:52:15 4 discovery-c[4,8,10,12]
Job queue header explained
|
A unique identifier that’s used by many Slurm commands when actions must be taken about one particular job. |
|
The node partition your job is running on. |
|
The name of your job |
|
The owner of the job |
|
The status of the job. (R)Running (PD)Pending (CG)Completing |
|
The time the job has been running until now. |
|
The number of nodes which are allocated to the job, while the NODELIST column lists the nodes which have been allocated for running jobs. For pending jobs, that column gives the reason why the job is pending. In the example, job 218983 is pending because requested resources (CPUs, or other) aren’t available in enough amounts, while job 219407 is waiting for another job whose priority is higher, to run. |
The scancel Command
Use the scancel command to delete a job, for example, scancel 8603 deletes the job with ID 8603. A user can delete his/her own jobs at any time, whether the job is pending (waiting in the queue) or running. The command skill will do the same.
Syntax: scancel <jobid> or skill <jobid>
scancel 219373Or
skill 219373| A user can’t delete the jobs of another user. |
The srun Command
srun is a multipurpose command that can be used in a submission script to create job steps and used to launch processes interactively via the terminal. For instance, If you have a parallel MPI program, srun takes care of creating all the MPI processes. Prefixing srun to your job steps causes the script to be executed on the compute nodes.
The srun command can be used in two ways:
-
In job scripts
-
Interactively
Srun used in a Job Script
#!/bin/bash
#SBATCH --job-name testJob
#SBATCH --output testJob.out
#SBATCH --ntasks 1
#SBATCH --cpus-per-task 1
#SBATCH --time 10:00
#SBATCH --mem-per-cpu 100M
srun echo "Start process"
srun hostname
srun sleep 30
srun echo "End process"
The srun command in this context will run your program as many times as specified by the --ntasks. For example, if --ntasks=2, every command in the job step will be executed twice.
|
Srun used Interactively
$ srun -n 1 --time=1:00:00 --partition=normal ./test.sh| The -n flag specifies the number of tasks (--ntasks) to run followed by the --time flag, for the duration and the --partition flag, for what partition(`normal, backfill, and so on. ) to run your job in. |
Srun Bash (Login Shell)
srun can also be used to run a login shell on the compute nodes and run commands interactively. Consider the below example.
srun -N 1 -n 2 -p backfill -t 00:02:00 --pty /bin/bash----Break down of the parts of the command into a table format:
-N |
The number of nodes to use. Same as --nodes |
-n |
The number of tasks to run. Same as --ntasks |
-p |
The partition to use. Same as --partition |
-t |
The execution wall time. Same as --time |
--pty |
The pseudoterminal (/bin/bash) |
Basically, the command above simply means that you want to run a login shell (/bin/bash) on the compute nodes. When the command is executed, you’ll automatically get an interactive session on one of the compute nodes after which you can then run your commands interactively. You are also put into the working directory from which you ran the launched session. It’s crucial to specify the --pty flag for this to work as intended.
Now that you are logged into one of the compute nodes, whatever command you run. For Example, srun hostname will be executed twice (-n 2), based on the value of the srun flags declared above. You can keep running as many commands as you want. But, bear in mind that your interactive session on the compute node you are currently on, will be killed when the wall time specified above elapses. Please see the example below.
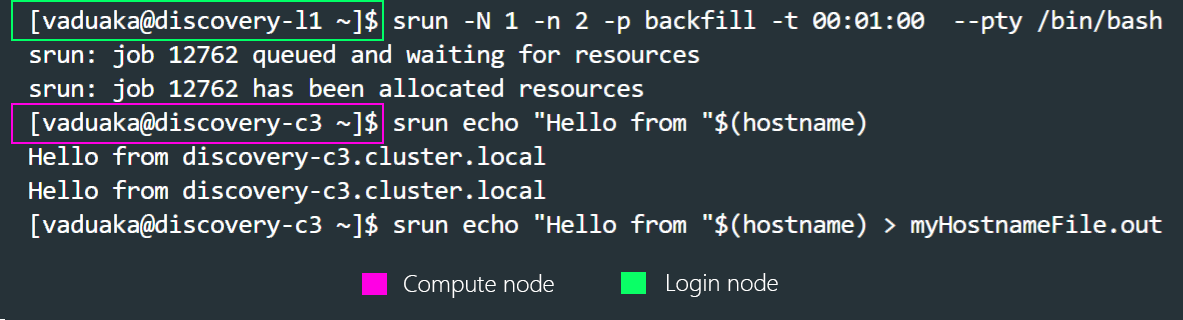
From the above image, one can infer that the session switch from the login node to one of the compute nodes after the srun command gets executed. You can also see the output of the second command executed on the compute node Hello from discovery-c3.cluster.local. Note that the last command sends your output to a file named myhostnameFile.out which eventually appears in the working directory from which you ran the launched session.
For more details on other useful srun flags please visit Slurm’S documentation on srun here  https://slurm.schedmd.com/srun.html
https://slurm.schedmd.com/srun.html
Srun for Parallel Execution
srun is mostly used in the context of executing a parallel job on a cluster managed by Slurm. It first creates a resource allocation in which to run the parallel job.
#!/bin/bash
#SBATCH --job-name testJob
#SBATCH --output testJob.out
#SBATCH --ntasks 4
#SBATCH --cpus-per-task 1
#SBATCH --mem-per-cpu 500M
#SBATCH --time 00:10:00
srun -n 1 sleep 10 &
srun -n 1 sleep 20 &
srun -n 2 hostname &
waitIn the example above, there are 3 job steps and 4 tasks in total which is equal to the total number of tasks in the srun declarations. Each task gets 1 CPU and each CPU gets 500mb of memory. This means that the last srun command will be executed twice.
The ampersand symbol at the end of every srun command is used to run commands simultaneously. This removes the blocking feature of the srun command which makes it interactive but non-blocking. It’s vital to use the wait command when using ampersand to run commands simultaneously. This is because it ensures that a given task doesn’t cancel itself due to the completion of another task. In other words, without the wait command, task 0 would cancel itself, given task 1 or 2 completed successfully.
The total number of tasks in the job step(srun -n flags) must be equal to the --ntasks value. Here, the -n flag and its value (1) in a serial execution context is used to specify the number of times a given program should be executed. For example, if srun -n 2 hostname is specified, the output will show hostname twice.
|
Srun for MPI Applications
The code below depicts an example of an MPI job resource request.
#!/bin/bash
#SBATCH --job-name=testJob
#SBATCH --output=testJob.out
#SBATCH --ntasks=8
#SBATCH --cpus-per-task=1
#SBATCH --ntasks-per-node=8
#SBATCH --mem-per-cpu 600M
#SBATCH --time 00:10:00
## Load MPI module
module load mpich/3.3.1-gcc-9.2.0-upe2lbc
## Number of threads to use
export OMP_NUM_THREADS=8
## Run MPI program
srun --mpi=pmi2 ./path/to/yourAppThis would request 8 tasks, which corresponds to 8 MPI ranks. Each of these tasks will have one core each and therefore constrained to run on one server --ntasks-per-node. Note that on the last line, the application gets executed with srun --mpi=pmi2 and not mpiexec or mpirun. This just ensures that the process mapping is consistent between MPI and Slurm. Also, the lines that begin with the double pound signs are comments that will definitely be ignored during processing. OMP_NUM_THREADS just regulates the number of threads to be used.
The sbatch Command
The main way to run jobs on "Discovery" is by submitting a script with the SBATCH command. The parameters or Slurm directives specified in the file script.sh will then be run as soon as the required resources are available. For example, assume that the batch file is named example.sh. To submit an SBATCH script, type the following command:
sbatch example.shOutput
Submitted batch job 9932