Message Passing Interface
Message passing interface (MPI) is a standard specification of message-passing interface for parallel computation in distributed-memory systems. MPI isn’t a programming language. It’s a library of functions that programmers can call from C, C++, or Fortran code to write parallel programs. With MPI, an MPI communicator can be dynamically created and have multiple processes concurrently running on separate nodes of clusters. Each process has a unique MPI rank to identify it, its own memory space, and executes independently from the other processes. Processes communicate with each other by passing messages to exchange data. Parallelism occurs when a program task gets partitioned into small chunks and distributes those chunks among the processes, in which such each process processes its part.
MPI Communication Methods
MPI provides three different communication methods that MPI processes can use to communicate with each other. The communication methods are discussed as follows:
Point-to-Point Communication
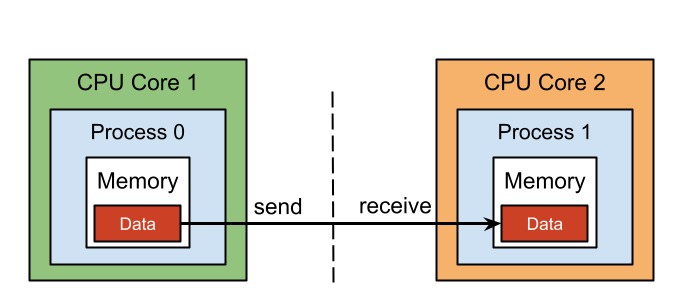
MPI Point-to_Point communication is the most used communication method in MPI. It involves the transfer of a message from one process to a particular process in the same communicator. MPI provides blocking (synchronous) and non-blocking (asynchronous) Point-to-Point communication. With blocking communication, an MPI process sends a message to another MPI process and waits until the receiving process completely and correctly receives the message before it continues its work. On the other hand, a sending process using non-blocking communication sends a message to another MPI process and continues its work without waiting to ensure that the message has been correctly received by the receiving process.
Common MPI Distribution
MPI isn’t a library implementation by itself, but rather, There are a vast majority of MPI implementations available out there. In this section, the most widely used vendor and public MPI implementations are discussed as follows.
Message passing interface chameleon (MPICH)
Message passing interface chameleon (MPICH) is a high-performance, open-source, portable implementation of message passing interface for parallel computation in distributed-memory systems distributed-memory. MPICH is the basis for a wide range of MPI derivatives including Intel MPI and MVAPICH among others. MPICH supports different parallel systems from multi-core nodes to clusters to large supercomputers. It also supports high-speed networks and proprietary high-end computing systems. For information, visit the MPICH home page.
Intel MPI Library
Developed by Intel, the Intel MPI Library implements the MPICH specification. A programmer can use the Intel MPI Library to create advanced and more complex parallel applications that run on clusters with Intel-based processors. In addition, the Intel MPI library provides programmers the ability to test and maintain their MPI applications. For more details, visit the Intel MPI Library home page.
MVAPICH
Developed by Ohio state university, MVAPICH is an MPI implementation over the InfiniBand, Omni-Path, Ethernet iWARP, and RoCE packages. It provides high performance, scalability, fault-tolerance support, and portability across many networks. For more information, visit the MVAPICH home page.
Open Message Passing Interface (OpenMPI)
Open message passing interface (OpenMPI) is an open-source implementation of MPI that’s maintained by large communities form industry and academia. It supports many different 32 and 64 bits platforms and networks including a heterogeneous network. Many of the largest systems on the top 500 supercomputers run OpenMPI. For details, visit the OpenMPI home page.