MPI Use Cases
In this section, different use of MPI parallel applications is discussed as follows
Parallel Computation
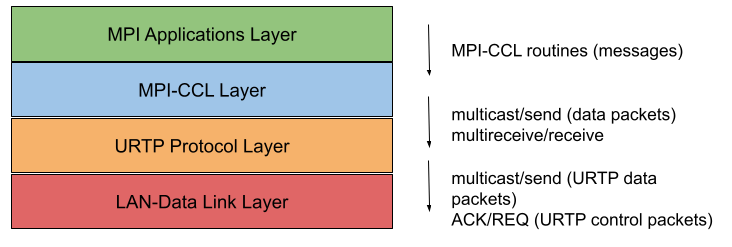
[1] proposed a system for parallel computations on clusters of workstations. As shown in figure 1, the system architecture consists of four software layers. The first layer is the MPI application layer. The second layer is the Collective Communication Library in MPI (MPI-CCI) layer. MPI-CCI is responsible for dividing messages into packets and exchanges packets with the other processes via various MPI send and receive routines. The third layer is the User-Level Reliable Transport protocol (URTP) layer. The forth layer is the LAN data-link layer. URTP interfaces with the LAN-data-link layer to leverage its broadcast medium for better collective communication performance. When an MPI program runs, a number of processes gets created, in which each process:
-
runs on a node of a cluster,
-
has its own memory space,
-
and communicates with the other processes via MPI point-to-point and collective messaging capabilities.
[2] proposed an MPICH-based parallel algorithm for the numerical solution of groundwater flux at evaporation from the water table. The algorithm uses a method called Richardson overrelaxation method to apply a numerical solution. Using message passing interface, the master process partitions the two dimensional rectangular grid into an equal amount of load and distributes it between the worker processes. Each process computes its part and sends the work result to the master process. The processes communicate with each other to exchange data using the MPI point-to-point communication method. The experimental results show about 58% efficiency in time.
References
[1] Jehoshua Bruck, Danny Dolev, Ching-Tien Ho, Marcel-Cătălin Roşu, and Ray Strong. 1995. Efficient message passing interface (MPI) for parallel computing on clusters of workstations. In Proceedings of the seventh annual ACM symposium on Parallel algorithms and architectures. Association for Computing Machinery, New York, NY, USA, 64–73.
https://doi.org/10.1145/215399.215421
[2] Masroor Hussain and Alex Kavokin. 2009. A 2D parallel algorithm using MPICH for calculation of groundwater flux at evaporation from the water table. In Proceedings of the 7th International Conference on Frontiers of Information Technology. Association for Computing Machinery, New York, NY, USA, Article 68, 1–4.
https://doi.org/10.1145/1838002.1838080
Image Processing
[1] proposed an MPI parallel algorithm for recursive image processing by filter 'mean'. At run time, a number of processes are created, each of which runs on a node of a cluster. One of those processes is the master process while the others are worker processes. The master process is in charged with the following:
-
Reading an BMP image file as an input,
-
Partitioning the image into part and distributing them between the worker processes,
-
Collecting the work results from the worker processes,
-
and writing the results into a file.
Each worker process is responsible for processing its part of the image. The processes use two MPI communication methods to exchange data between them. The master process uses collective communication to send common information to work processes. All processes use Point-to-point communication to exchange data between two processes. Several experiments have been conducted comparing the parallel algorithm to its serial version, and the parallel algorithm showed significant speed-up over the serial version.
References
[1] Atanaska Bosakova-Ardenska, Simeon Petrov, and Naiden Vasilev. 2007. Implementation of parallel algorithm conveyer processing for images processing by filter 'mean'. In Proceedings of the 2007 international conference on Computer systems and technologies. Association for Computing Machinery, New York, NY, USA, Article 20, 1–6.
https://doi.org/10.1145/1330598.1330621
Parallel File Systems
The conventional implementation of Linux file tree walk isn’t suitable for parallel file systems. It serially traverses the file system tree for any I/O operations, which is a performance bottleneck for parallel systems. To address this issue, several parallel implementations of the file system tree walk were implemented. For instance, at Los Alamos National Laboratory, a tool called MPI file tree walker (MPI-FTW) for a parallel node exploration was developed using a message passing interface (MPI) [1]. The design of the tool follows a centralized task distribution paradigm. The master process is responsible for managing a work queue of unexplored directories, equally distributing works between processes, and collecting work results from worker processes. The worker processes, on the other hand, are responsible for directory traversal. The MPI-FTW tool showed a significant speed-up over the serial version of Linux file tree exploration.
Another study [2] proposed the implementation of three parallel file tree walk algorithms using message passing interface. The first algorithm is called Distributed random queue splitting algorithm (DRQS). With the DRQS algorithm, there is no centralized master process. Each process runs on a node of a cluster and has a local work queue to process. When a work queue of a process is empty, the process sends a work request to a random remote process. When the remote process receives the work request, it checks its work queue for any pending work. If its queue still have pending works, it splits pending works into parts and distributes them equally between the requesters including itself. Otherwise, the process sends a negative response to each requester. The MPI communication between the processes is performed asynchronously, in which a process can periodically initiate or satisfies work requests while continuing its work.
The second algorithm is called Proximity Aware Distributed Random Queue Splitting algorithm (PA-DRQS). With PA-DRQS, multiple processes can run concurrently on a node of a cluster. When a process requests work to process, its request is assigned to the processes in increasing order of their distance from the requester. The third algorithm is called Hybrid Distributed Random Queue Splitting (H-DRQS) algorithm. With H-DRQS, a number of light weight processes (threads) can be created on each compute code. While all threads on a node have access to a shared work queue, one thread is allowed to participate in MPI communication such as requesting and receiving work requests.
References
[1] Sutton, Christopher Robert, "Performance, Scalability, and Robustness in Distributed File Tree Copy" (2018). Boise State University Theses and Dissertations. 1444. 10.18122/td/1444/boisestate
[2] J. LaFon, S. Misra and J. Bringhurst, "On distributed file tree walk of parallel file systems," SC '12: Proceedings of the International Conference on High Performance Computing, Networking, Storage, and Analysis, 2012, pp. 1–11, https://ieeexplore.ieee.org/document/6468454